- git-sparse-checkout - Reduce your working tree to a subset of tracked files
- Bring your monorepo down to size with sparse-checkout
本文发表于 2020 年 1 月 17 日,2021 年 3 月 31 日有更新,原文见 Bring your monorepo down to size with sparse-checkout。作者 Derrick Stolee 从 2017 年开始为 Git 项目贡献代码,主要专注于性能方面。成果包括
git log --graph速度优化和针对巨型代码库执行git push命令的速度优化。限于译者水平,本文并未逐字逐句翻译,有些位置亦有段落内容的重排和删减,有难以理解之处还请阅读原文。
代码目录不断膨胀失去控制,checkout 和 status 命令运行迟缓。当只是需要修改代码中的一小部分时,这些问题尤其令人头疼。稀疏检出特性将允许开发者专注于一小部分文件,特别是在处理“有大量微服务的单一代码库(monorepo)”时,即不会破坏单一代码库模式的优点,又能保持工作流程简单快速。Git 2.25.0 引入了实验性的 git sparse-checkout 命令,改进了现有特性的易用性,有助于提升加载大型项目的性能。
稀疏检出功能已在 git 1.7 实装,启用需要设置
core.sparseCheckout和.git/info/sparse-checkout等内容。git 2.25.0 之后这些工作可以通过git sparse-checkout命令完成。
monorepo 的主旨就是将所有代码存储在同一个版本控制(VCS)代码库中。另一种选择是把服务、应用、库的代码存储在不同的版本控制库中,在 Git 的思路下可以使用 subtree 和 submodule 组合。
已存在的仓库启用稀疏检出
执行如下命令
$ git sparse-checkout init --cone
$ git sparse-checkout set <dir1> <dir2> ...
如果给你整懵了,还可以用 git sparse-checkout disable 恢复原样。
init 子命令对 git 进行了必要的配置,并在 .git/info/sparse-checkout 配置了基本的模式:“仅匹配根目录下的文件”。
set 子命令向 .git/info/sparse-checkout 添加模式。注意紧接在指定目录的父目录中的所有文件也会被匹配。例如对 git sparse-checkout set A/B 而言,A/B/C.txt 可以匹配(A/B 的直接子代),A/D.txt 可以匹配( A/B 的直接同级),E.txt 也可以(A 的直接同级)。模式的语法同 .gitignore 类似。
单一代码库中的微服务示例
作者创建了一个示例仓库 derrickstolee/sparse-checkout-example,模拟了一个照片存储和分享的应用程序。仓库保存了许多微服务以及三种客户端的代码,其结构如下:
client/
android/
electron/
iOS/
service/
common/
identity/
list/
photos/
web/
browser/
editor/
friends/
boostrap.sh
LICENSE.md
README.md
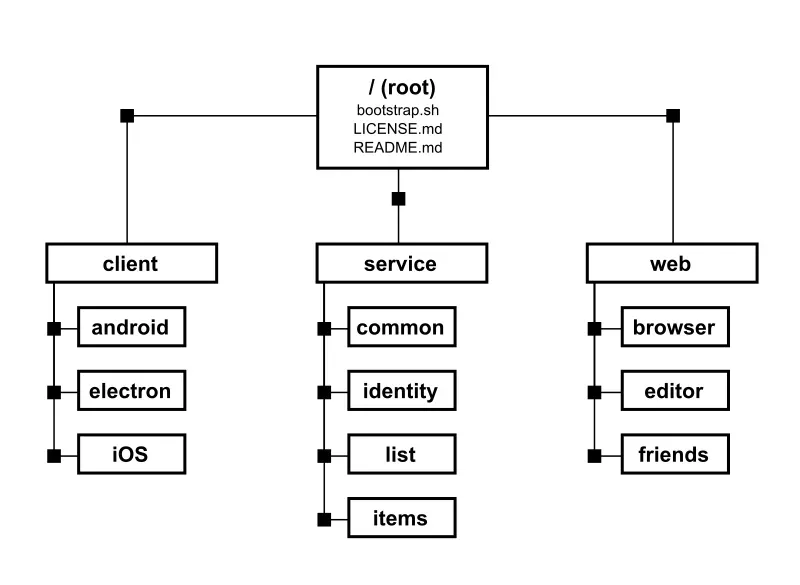
如此多互不相关的代码堆放在一个仓库中,使用者并不需要详细了解每一个目录,然而在 fetch 和 merge 时这些文件又都同样重要。
$ ls
bootstrap.sh* client/ LICENSE.md README.md service/ web/
$ find . -type f | wc -l
1590
事实上这都算少了,想象一下在文件数后面加 3 个 0 吧。
执行 git sparse-checkout init --cone 让工作目录里只留有根目录下的文件(以及 .git 目录)。
$ git sparse-checkout init --cone
$ ls
bootstrap.sh* LICENSE.md README.md
$ find . -type f | wc -l
37
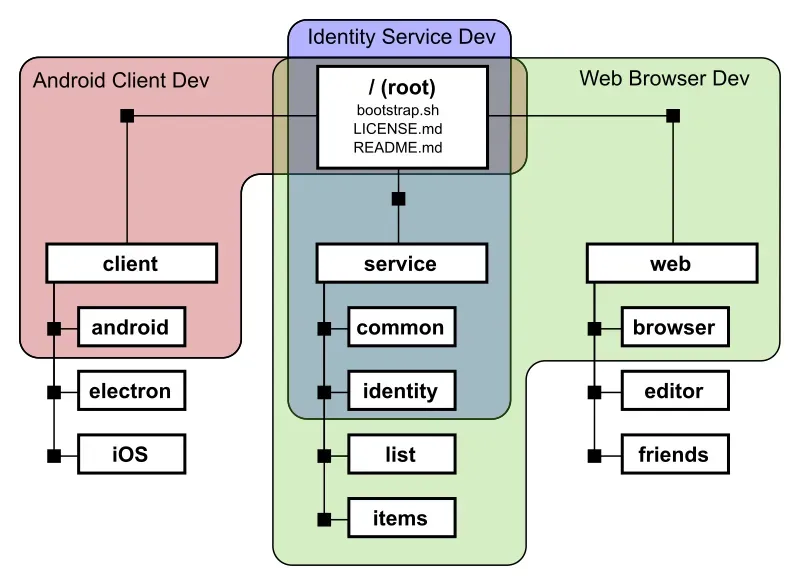
Android 客户端开发团队只需要 client/android 下的内容。
$ git sparse-checkout set client/android
$ ls
bootstrap.sh* client/ LICENSE.md README.md
$ ls client/
android/
$ find . -type f | wc -l
62
项目管理员可以在根目录下创建一个 boostrap.sh 脚本,引导不同团队使用更复杂的文件匹配模式。例如负责身份验证的团队除了自身的代码还需要一个公用服务。
$ ./bootstrap.sh identity
Running ‘git sparse-checkout init --cone’
Running ‘git sparse-checkout set service/common service/identity’
网页客户端的照片浏览器小组则需要不同的代码目录。
$ ./bootstrap.sh browser
Running ‘git sparse-checkout init --cone’
Running ‘git sparse-checkout set service web/browser’
以稀疏模式复制仓库
在新复制一个仓库时使用 --no-checkout 选项防止工作目录被一大堆文件快速塞爆。
$ git clone --no-checkout https://github.com/derrickstolee/sparse-checkout-example
Cloning into 'sparse-checkout-example'...
remote: Enumerating objects: 14, done.
remote: Counting objects: 100% (14/14), done.
remote: Compressing objects: 100% (12/12), done.
remote: Total 1901 (delta 1), reused 11 (delta 1), pack-reused 1887
Receiving objects: 100% (1901/1901), 170.91 MiB | 74.79 MiB/s, done.
Resolving deltas: 100% (181/181), done.
$ cd sparse-checkout-example/
$ git sparse-checkout init --cone
$ git checkout main
$ ls
bootstrap.sh LICENSE.md README.md
Cone mode: restricted patterns improve performance
在大型项目中,模式匹配对性能的影响也是显著的。在
cone mode下,匹配更加严格速度更快。这一小节涉及文件匹配模式对性能的影响,建议阅读原文,不作翻译。要启用cone mode,使用git sparse-checkout init --cone。
稀疏检出和部分拷贝
稀疏检出仍然会复制整个仓库,只是检出用户需要的目录。所以如果代码仓库以 GB 论,新复制仓库时只检出
README文件并不能节省什么时间和流量。
由于开发人员只需要下载部分文件,稀疏检出和部分拷贝一起使用可以更显著地加速工作流程。
$ git clone --filter=blob:none --no-checkout https://github.com/derrickstolee/sparse-checkout-example
Cloning into 'sparse-checkout-example'...
remote: Enumerating objects: 42, done.
remote: Counting objects: 100% (42/42), done.
remote: Compressing objects: 100% (41/41), done.
remote: Total 393 (delta 19), reused 6 (delta 1), pack-reused 351
Receiving objects: 100% (393/393), 81.13 KiB | 509.00 KiB/s, done.
Resolving deltas: 100% (33/33), done.
$ cd sparse-checkout-example
$ git sparse-checkout init --cone
$ git checkout main
remote: Enumerating objects: 2, done.
remote: Counting objects: 100% (2/2), done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 1 (delta 0), pack-reused 1
Receiving objects: 100% (3/3), 1.41 KiB | 1.41 MiB/s, done.
Updating files: 100% (3/3), done.
Already on 'main'
Your branch is up to date with 'origin/main'.
$ git sparse-checkout set client/android
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 26 (delta 0), reused 1 (delta 0), pack-reused 23
Receiving objects: 100% (26/26), 985.91 KiB | 1.19 MiB/s, done.
Updating files: 100% (26/26), done.
$ tree -L 3
.
├── LICENSE.md
├── README.md
├── bootstrap.sh
└── client
├── README
└── android
├── README.md
├── app.js
├── auth.js
├── config.js
├── images
├── package-lock.json
├── package.json
├── static
└── views
5 directories, 10 files
--filter=<filter-spec>在 clone 时过滤 blob 对象(文件内容),--filter=blob:none会过滤所有 blob 而--filter=blob:limit=<size>会过滤大小超过限制的 blob
在这个例子中,复制整个仓库只使用了 393 个对象,注意每一次 git 指令输出的 Receiving objects 行,初始化时只下载了 3 个对象,而拉取 client/android 目录时只下载了 26 个对象。