笔者正在开发一款通过模版生成文档的工具库,暂定命名为 Motto。随着开发的进行,觉得实在是没有什么整合的必要,于是这个项目就拆分成了两个相互独立的代码库,motto-html 和 motto-pdf-itext8。
motto-pdf-itext8 使用 iText8 填充 PDF 中的 AcroForm 表单,生成最终的 PDF 文件。你可以通过 GitHub 访问本项目,或通过 Maven 中央仓库拉取项目 cc.ddrpa.motto:motto-pdf-itext8。
相较于 motto-html,这个方案对模版的制作者更为友好 —— 你可以使用 Microsoft Word 创建好底版,导出 PDF 后在福昕 PDF 编辑器或 Adobe Acrobat DC 中添加 AcroForm 表单。近年来 LibreOffice 也支持了直接创建含有 AcroForm 的 PDF 文件。
当然,这个方案的表达能力会有一些欠缺。假如你要实现打印一周账单流水的功能,就需要尽可能多地为一些行和单元格标上号,然后按序填充这些单元格。如果格子还是不够,需要在换页时复制一个全是单元格的 Page 继续填充免得露出破绽。用 motto-html 来做的话,一个循环标记也许就搞定了。
此外,支持编辑 PDF 的程序大多是价格不菲的商业软件(尤其是只用上了编辑表单这个功能时,就更显得昂贵了)。Scribus 是笔者找到的不多的开源替代之一,不过就当前而言(2024 年 6 月),对 CJK 字符的支持貌似还聊胜于无。Flying Saucer 已经支持将 HTML 中的几种 <input> 元素转换为 AcroForm,也不失为一种方案,但是你都这样了,直接将数据填充到 HTML 中岂不是更好?
一开始由于路径依赖,笔者选择了 Apache PDFBox 3,不过在尝试过程中又接触了 iText 8。后者的文档似乎要更详细一点,因此虽然笔者更喜欢 PDFBox 的 API 风格,最终还是选择了后者。使用者可能需要注意下 Apache PDFBox 的开源许可证是 Apache,而 iText 使用 AGPL。
用来创建 PDF 文档的方式也有一些注意事项,例如使用 LibreOffice 创建 TextBox,设置字体为 Noto Sans CJK SC, Regular, 20,导出后使用 pdftk 解压这个文件 ,可以看到字体样式丢失,变为 Helvetica 和 8pts。如果设置 TextBox 的 Default Text,字号信息得到了保留,字体仍然是 Helvetica。
在论坛上也可以看到类似的反馈,例如 PDF list and combo box fields use wrong font in exported PDF 、Fillable forms - text box, font styles and export pdf issues 和 PDF form created in Libre Office - trouble with form fields and font sizing,还有人提到类似的问题也会出现在 Scribus 中,而 Acrobat DC 系列产品则不受影响。
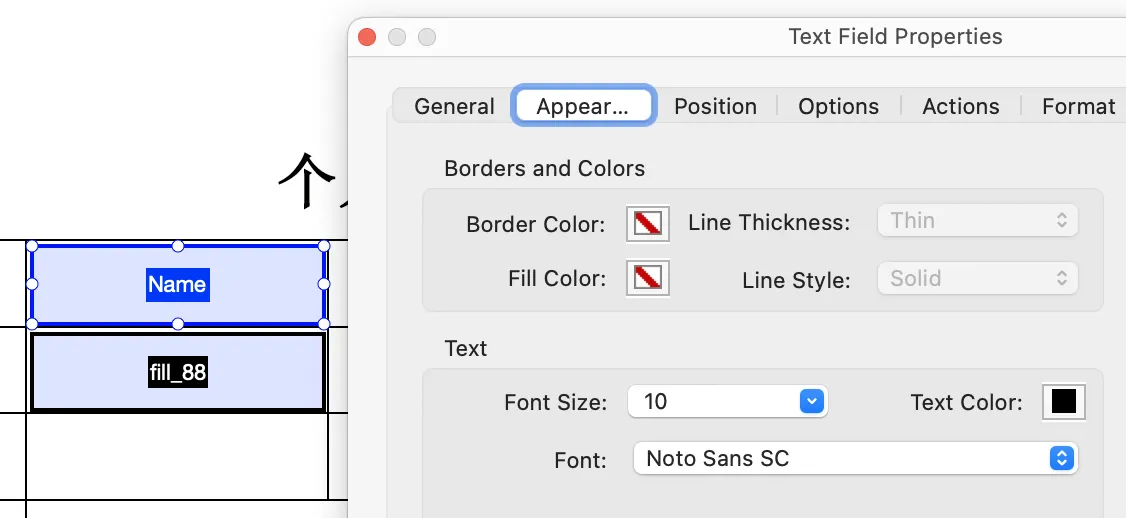
如图在 Acrobat DC 中设置 Text Field 的字体为 Noto Sans SC,字号为 10,在 iText 或 PDFBox 中获取 DefaultAppearance 会得到 /NotoSansSC-Regular 10 Tf 0 g,其中 Tf 操作符之前的部分就是该 Text Field 的样式。同样地,设置另一个 Text Field 的字体为 Noto Serif SC,字号 auto,则会得到 /NotoSerifSC-Regular 0 Tf 0 g,
编辑 PDF 时使用的字体也会有一些限制,例如在 Acrobat DC 中选择字体使用 SimSong 时就会得到提示:
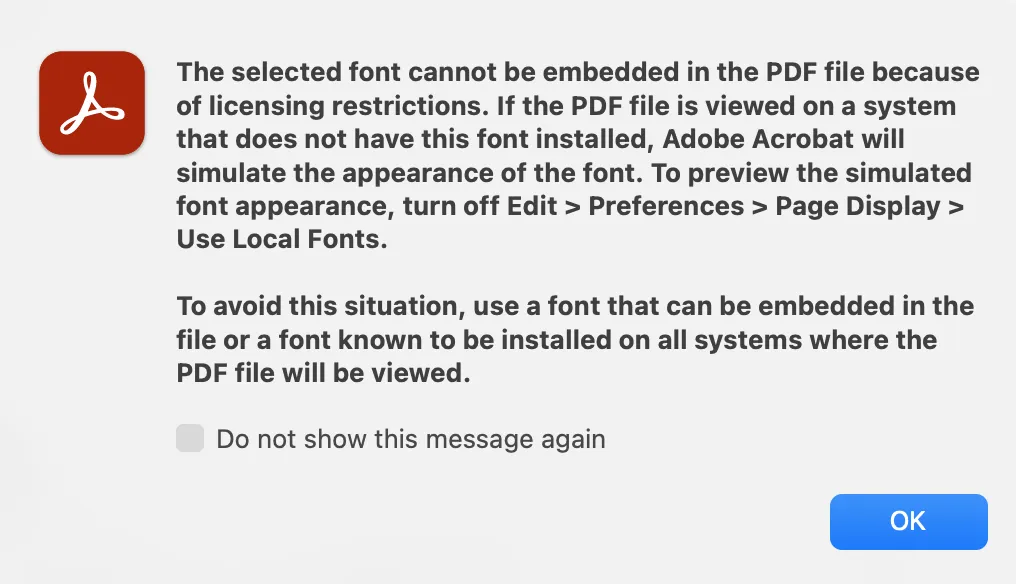
而如果你试图在程序中添加一些字体,则可能得到一些异常提示,例如 cannot be embedded due to licensing restrictions.。
一些其他工作
为渲染的文本选择合适的字体
Another case for the PDF detectives: The mystery of the disappearing / appearing text 展示了如何使用 com.itextpdf.layout.font.FontSelectorStrategy 检测文本内容选择合适的字体。
可以用作 cc.ddrpa.motto.pdf.itext.MottoFontAgent 的 fall-back 机制。当 MottoFontAgent 无法找到与样式声明能够对应的字体时,就会根据文本内容挑选并返回字体。
识别单选框、复选框和图片表单
单选框、复选框和图片表单都是靠 com.itextpdf.forms.fields.PdfButtonFormField 实现的。
boolean isRadio() 方法能够判断这个对象是不是一个单选框(组)。
如果一个 PdfButtonFormField 是个复选框,那它的 PdfObject 属性转换为字符串看起来会像是这样:
<</AP <</D <</Off 191 0 R /Yes 192 0 R >> /N <</Off 189 0 R /Yes 190 0 R >> >> /AS /Yes /F 4 /FT /Btn /MK <</BC [0.0 ] /BG [1.0 ] >> /P 34 0 R /Rect [77.8142 388.46 95.8142 406.46 ] /Subtype /Widget /T CheckBoxRow1 /Type /Annot /V /Yes >>
所以如果一个 PdfButtonFormField 的 PdfObject 包含了 /Off,则可能是个复选框,如果还包含了 /Yes,则这个复选框应该属于选中状态。
其他情况在本项目中就按照图片处理了。
插入图片
PdfButtonFormField 提供了 PdfButtonFormField setImage(String filePath) 和 PdfButtonFormField setImageAsForm(PdfFormXObject form) 两种方法向文档中插入图片。
不知为何,通过后者插入的图片正常嵌入了生成的 PDF 文件(文件体积正好增大了这么多),PDF 阅读器却无法看到。使用 Adobe Acrobat 编辑这个 PDF,可以看到图片上多了一个遮罩,手动移除就显现出来了。
查看前者的实现,发现实现方式是文件流读取文件后转成 Base64 编码的字符串,然后调用 setValue 方法直接写入表单。
InputStream is = new FileInputStream(image);
String str = Base64.encodeBytes(StreamUtil.inputStreamToArray(is));
return (PdfButtonFormField) setValue(str);
这下就好办了。