个人隐私安全和其它安全问题一样,是一个永远做不完的需求。你不能说你的网站是绝对安全的,只能说「我检查了所有目前已发现的安全漏洞列表,并且采取了相应的防御措施,做到尽量安全」,或者说「我们采取了一些很好的安全实践,比如采取了动态密码、在 NGINX 上安装了防攻击防 SQL 注入插件」等等。
什么是隐私数据
- 个人身份信息(PII, Personally Identifiable Information),例如姓名、证件号码(身份证、驾照、护照等)、银行账号 / 信用卡号、电话号码、电子邮箱、可以关联到个人的资产信息(IP、MAC 地址等)、地址、生物识别数据(指纹、人像、虹膜、声纹等)等,以及由用户数据产生的各种组合
- 个人财务信息(PFI, Personal Financial Information),例如账单、资产记录、信用记录等
- 受保护的健康信息(PHI, Protected Health Information),例如病历、就诊记录、医学报告、账单等
- 密码
- ……
PII 是个人信息的核心。一般情况下,PFI 和 PHI 脱离了 PII 之后,就不再具有隐私信息的特征。
如何保护隐私安全
映射
隐私数据泄漏的一大来源就是公民身份证号。从结果反推大概有这样几个用途:
- 作为唯一标识符
- 与其他信息系统交互(其实也部分归因于上一条原因)
如果根本就不使用敏感信息,又怎么会发生泄露呢?
不跨越信息系统传递数据时,我们并不需要明文身份证号码作为唯一标识符,事实上,一个无碰撞的哈希函数输出也可以。
强无碰撞性:对于一个哈希函数 ,无法找到 满足
弱无碰撞性:对于一个哈希函数 以及 ,无法找到另外一个 满足
Use Fast Data Algorithms 提到 MD5 是一种缓慢的哈希算法,然而文章作者也提到 要根据业务场景具体分析。
2022 年我所在的城市人口大约有两百多万,使用身份证号码编码规则(校验位计算规则除外)生成 3,000,000 条不重复的身份证号码,然后使用 java.security.MessageDigest 的 MD5 方法和 org.lz4:lz4-java:1.8.0 提供的两种 XXHash 方法计算哈希值。
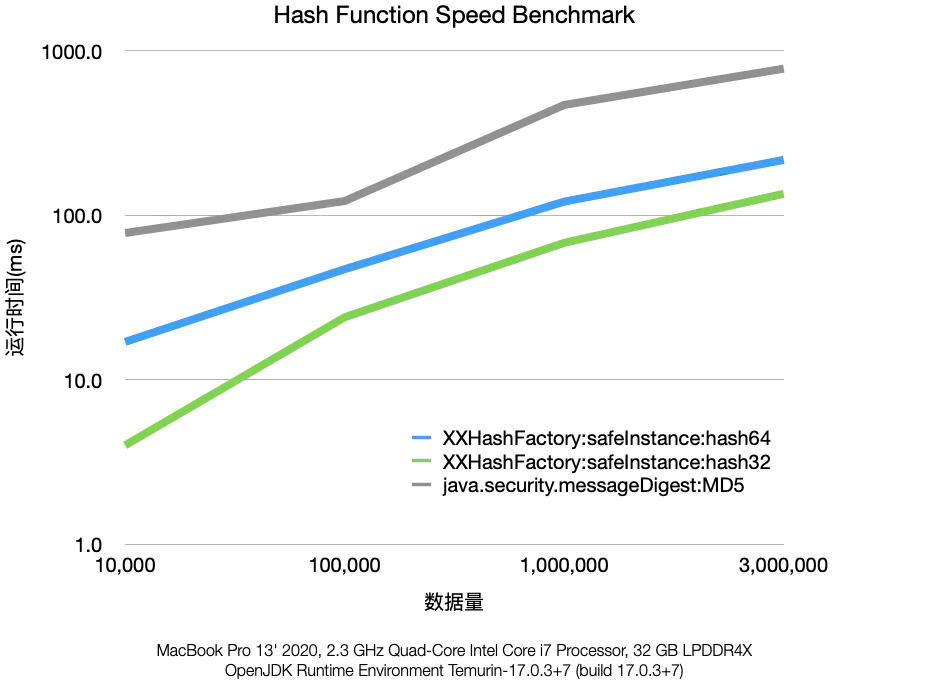
虽然测试比较粗糙(比如没有给机器充分预热,使用相同负载连续多次测试取平均值,调整 JVM 参数等),从时间上看结果也并非不可接受(遗憾的是 XXHash32 发生了碰撞,不过应用到生产环境时我们可以结合其他信息进一步缩小碰撞的概率)。
脱敏
另一种方案是脱敏。业主方未给出脱敏方案的,可按本建议执行。
| 类型 | 方法 | 示例 | 说明 |
|---|---|---|---|
| 密码 | 不输出 | 密码、密钥、验证码、Hash、salt | |
| 会话 ID | 前 5 后 5 | 7SuA8***Ttslb |
包括 Web 应用的会话标识、设备指纹、验证 token 等 |
| 身份证号 | 前 1 后 1 | 3***X |
包括其他个人身份证件类型 |
| 姓名 | 前 1 后 1 | 李*明 |
无论总长多少,保留第一个字和最后一个字,中间添加 * |
| 银行卡号 | 前 6 后 4 | 62266***0831 |
|
| 手机号 | 前 3 后 4 | 133***9574 |
|
| 电子邮箱 | 前 1 后 1 | y***n@live.com |
不需要处理服务提供商域名部分 |
| 地址 | 隐去门牌号码 | 上海市市辖区浦东新区外高桥保税区*号*室 |
|
| IP(IPv4) | 隐藏中间两段 | 220.***.***.161 |
避免在 URL 中出现个人隐私信息
一个通过身份证号码查找用户的 RESTful API 很可能会长这样: /user/:idcard。对这个接口的请求会不可避免地出现在反向代理服务器、Web 服务器、负载均衡器的访问日志中,暴露用户的身份证号码。
视实现场景可以用多种方法避免这个问题:
- 不要将敏感字段用作唯一标识符,改用随机 ID
- 将敏感值放在 POST 请求的请求体中,然后通过 HTTPS 提供服务
对象打印重写 toString 方法
为了方便查找定位问题,或者是在使用 SLF4J 这样的 API 时预防空指针异常,日志 API 可能会接收整个对象。
// 需要记录的信息
logger.info("login user is {}", user.useId);
// 实际代码
logger.info("login user is {}", user);
在 Java、JavaScript 等语言的主流日志框架中,这个操作很可能只是在调用 toString 方法,因此日志将会打印 user 对象的所有内容,包括用户的 passwordHash。可以重写对象的 toString 方法来避免这个问题。
class UserAccount {
id:string
username:string
passwordHash:string
// ...
public toString(){
return `UserAccount(${this.id})`;
}
}
关注日志级别
有些 ORM/Web 框架会把查询请求和响应结果以 INFO 级别输出到日志中。
主动把这些日志输出降级为 DEBUG 或 TRACE,不然 Spring Boot Actuator 等监控工具可能会“过于热情地”为你记录下这些敏感信息。
在生产环境中把日志过滤提高到 WARN 级别(这也是为了读日志的人考虑)。
QA 和自动化测试
可以被动式地监控日志数据,例如出现 18 个数字(或 17 个数字加字母 X)组合序列时,触发身份证号码规则验证,如果验证通过则发出警报,不过这种方法存在一定的误判率。
也可以主动出击,例如一个用户注册的场景,测试人员可以模仿用户在 Web 前端表单填写姓名、Email 的行为,然后搜索这些信息是否被记录到了日志里。整个流程最终可以在 CI/CD 流水线上自动完成。
Data Loss Prevention
有一些工具 / 框架 / 服务可以检测文本内容中的敏感数据并对其进行分类。给定文本输入后,DLP 工具会返回文本中找到所有可能的信息泄漏点。
日志打码
在多服务系统中,日志收集工具是日志到达日志中心的必经之地,可以在这里对所有服务的日志做集中式的处理,例如编写代码用正则表达式查找和替换敏感信息。
Code Review 中的人工审查
Code Review 是开发过程中可以保证代码质量的部分,可以探讨程序漏洞、健壮性问题、改进建议等等,检查清单上也可以添加日志代码的检查项。