笔者正在开发一款通过模版生成文档的工具库,暂定命名为 Motto。随着开发的进行,觉得实在是没有什么整合的必要,于是这个项目就拆分成了两个相互独立的代码库,motto-html 和 motto-pdf-itext8。
motto-html 使用 Apache Velocity 模版引擎创建 HTML 文档,然后用 Flying Saucer 转换为 PDF 文档。你可以通过 GitHub 访问本项目,或通过 Maven 中央仓库拉取项目 cc.ddrpa.motto:motto-html。
Flying Saucer is a pure-Java library for rendering arbitrary well-formed XML (or XHTML) using CSS 2.1 for layout and formatting, output to Swing panels, PDF, and images.
本文写作时,Flying Saucer 的最新版本为 9.8.0,本文使用的例子均基于该版本。代码稍作修改也可以用于 JDK 11 和 Flying Saucer 9.5.2(从 9.5.0 版本开始 Flying Saucer 需要 JDK 11,从 9.6.0 版本开始需要 JDK 17)。如果你的项目还停留在 JDK 8,由于 Flying Saucer 的早期版本和现版本差的有些多了,我建议:
- 切换到 JDK 11,一般应用场景下它们不会有显著的区别,单元测试跑一跑应该能一次通过;
- 考虑使用其他方案,例如 motto-pdf-itext8;
要完成 HTML 转换 PDF 的工作,只需要引入 org.xhtmlrenderer:flying-saucer-pdf 依赖,这个包是用来替换 org.xhtmlrenderer:flying-saucer-pdf-openpdf 的,依靠 OpenPDF 项目实现了操作 PDF 的能力。你还可以在 mvnRepository 上找到 org.xhtmlrenderer:flying-saucer-pdf-itext5,是利用 iText 5 的版本,二者的 API 有细微的差别。
制作模板
Flying Saucer 支持了一小部分 CSS3 的特性,例如页面控制。可以在 HTML 文档中指定样式:
@page {
/* A4 大小,竖版 */
size: A4 portrait;
/* 或者横版 size: A4 landscape;*/
/* 用 margin 指定页边距也是支持的 */
}
你可以参考 How do you control page size?,对手动分页等内容也做了详细的说明。
此外,在创建模版时还需要注意:
- 模板样式应当遵循 Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification;
- 尽管
<img>这类标签支持自闭合,请使用<img></img>; - 使用
pt设置图像元素的尺寸,特别是在使用了EmbeddedImage#setDevicePixelRatio的情况下; - 设置字体族(
font-family)时,首选项必须是STSong/STSongStd或其他预先部署到服务器环境并由程序显式读取的字体; - 观察到
E > F这种 Child selectors 在某些情况下似乎没有正确的应用font-family属性,因此如果输出文件中没有出现字符,请在 DOM 元素上通过内联样式设置font-family; - 请把
<style>标签放在<head>里,不要放在<body>之中或之后; - 请使用 Ctrl + P 或 Cmd + P 预览效果,而不是 DevTools;
- 不要尝试在模版内使用 JavaScript;
支持 CJK 字符
和其他 PDF 编辑工作流一样,由于 Base 14 字体不包含中文字符,需要额外加载一些字体。
Flying Saucer 默认支持了一批中文字体,你可以在 org.xhtmlrenderer.pdf.CJKFontResolver 中查看这些字体的 family name,名字中的 -V 后缀表示这些字体用于纵向排版。
private static final String[][] cjkFonts = {
{"STSong-Light-H", "STSong-Light", "UniGB-UCS2-H"},
{"STSong-Light-V", "STSong-Light", "UniGB-UCS2-V"},
{"STSongStd-Light-H", "STSongStd-Light", "UniGB-UCS2-H"},
{"STSongStd-Light-V", "STSongStd-Light", "UniGB-UCS2-V"},
{"MHei-Medium-H", "MHei-Medium", "UniCNS-UCS2-H"},
{"MHei-Medium-V", "MHei-Medium", "UniCNS-UCS2-V"},
{"MSung-Light-H", "MSung-Light", "UniCNS-UCS2-H"},
{"MSung-Light-V", "MSung-Light", "UniCNS-UCS2-V"},
{"MSungStd-Light-H", "MSungStd-Light", "UniCNS-UCS2-H"},
{"MSungStd-Light-V", "MSungStd-Light", "UniCNS-UCS2-V"},
{"HeiseiMin-W3-H", "HeiseiMin-W3", "UniJIS-UCS2-H"},
{"HeiseiMin-W3-V", "HeiseiMin-W3", "UniJIS-UCS2-V"},
{"HeiseiKakuGo-W5-H", "HeiseiKakuGo-W5", "UniJIS-UCS2-H"},
{"HeiseiKakuGo-W5-V", "HeiseiKakuGo-W5", "UniJIS-UCS2-V"},
{"KozMinPro-Regular-H", "KozMinPro-Regular", "UniJIS-UCS2-HW-H"},
{"KozMinPro-Regular-V", "KozMinPro-Regular", "UniJIS-UCS2-HW-V"},
{"HYGoThic-Medium-H", "HYGoThic-Medium", "UniKS-UCS2-H"},
{"HYGoThic-Medium-V", "HYGoThic-Medium", "UniKS-UCS2-V"},
{"HYSMyeongJo-Medium-H", "HYSMyeongJo-Medium", "UniKS-UCS2-H"},
{"HYSMyeongJo-Medium-V", "HYSMyeongJo-Medium", "UniKS-UCS2-V"},
{"HYSMyeongJoStd-Medium-H", "HYSMyeongJoStd-Medium", "UniKS-UCS2-H"},
{"HYSMyeongJoStd-Medium-V", "HYSMyeongJoStd-Medium", "UniKS-UCS2-V"}
};
可以简单创建一个 PDF 文档,预览这些字体的效果。笔者用 Apache Velocity 模版引擎做了个简单的循环:
#foreach( $font_family in $all_font_families )
<p>$font_family</p>
<p style="font-family: $font_family">SC: 子曰:“学而时习之,不亦说乎?有朋自远方来,不亦乐乎?人不知而不愠,不亦君子乎?”</p>
<p style="font-family: $font_family">TC: 子曰:「學而時習之,不亦說乎?有朋自遠方來,不亦樂乎?人不知而不慍,不亦君子乎?」</p>
#end
在这么多字体中,似乎只有 STSong 和 STSongStd 在显示简体中文内容时不会出现错误或缺失字形(那为什么繁体中文部分也有问题呢?因为港台的繁体中文也不太一样,例如 Noto 就将中文字体分为了 TraditionalChinese 和 TraditionalChineseHK)。

互联网搜索结果表明 STSong 似乎应该是华文宋体,而文档中看起来像是某种黑体。在 Font Book(macOS)中预览 STSong,样式也不太一样:
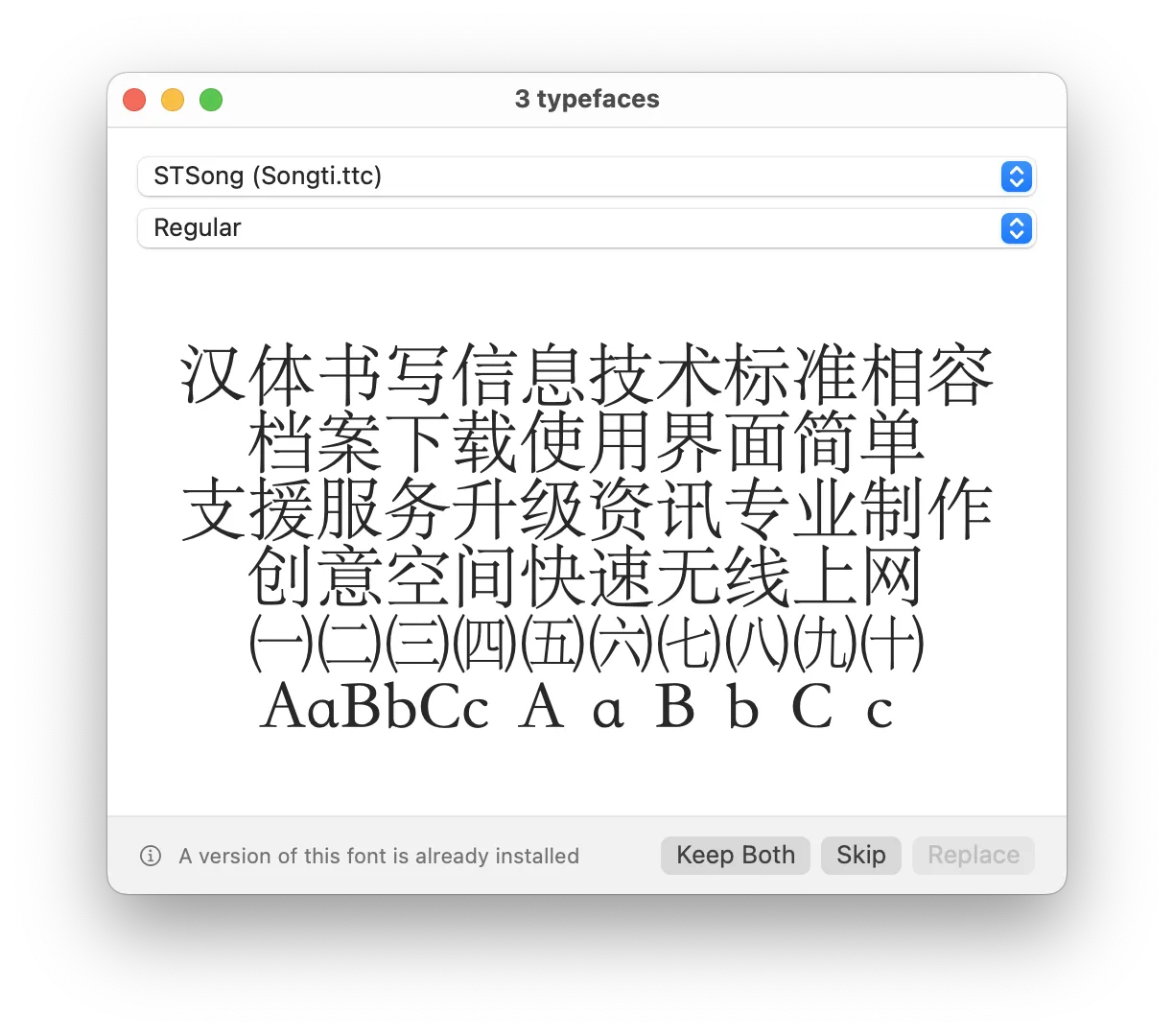
如果你认为「宋体还是黑体」不是个问题的话,唯二需要注意的点就是:
1)出于性能优化的目的,Flying Saucer 9.2.0 以及之后的版本中需要具体指定 org.xhtmlrenderer.pdf.CJKFontResolver 实例作为 ITextRenderer 的 FontResolver 才能够加载这些 CJK 字体。你可以查看 #184 avoid loading CJK fonts by default 了解事情的经过,不过简单来说就是:
CJKFontResolver fontResolver = new CJKFontResolver();
ITextRenderer renderer = new ITextRenderer(fontResolver);
- 在要用于生成 PDF 文件的 HTML 文档中,指定 DOM 元素的
font-family为STSong-Light-H或STSongStd-Light-H。
如果你决定嵌入自己的中文字体,那 CJKFontResolver 就不那么重要了。
从 Windows 11 中复制出中易宋体 SimSun.ttc:
fontResolver.addFont("/Users/yufan/Library/Fonts/SimSun.ttc", BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
BaseFont.IDENTITY_H 指定这个字体的编码(encoding)按 Unicode/UTF-8 处理,否则就是默认的 Latin-1。BaseFont.EMBEDDED 表明字体会被嵌入到文档中,以便在其他设备上显示 / 使用。虽然没有像 iText8 那样提供 BaseFont.PREFER_EMBEDDED 这样的选项,别担心,不会把没用到的字形也放进去的。
.ttc 扩展名表明这个文件是一个 TrueType® font collection,也就是字体集合。执行上述代码将会分别注册 family name 为 SimSun 和 NSimSun 的两种字体。如果你用不着这么多字体,一种方法是在字体文件路径后添加 ,$FONT_INDEX 后缀,只注册合集中的某个字体,例如:
fontResolver.addFont("/Users/yufan/Library/Fonts/SimSun.ttc,0", BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
如果你打算像这个例子一样从自己的 Windows 或者 macOS 里拷一些字体出来的话,可能会碰上一些版权要求比较严格的字体,程序在添加这些字体时会抛出异常 cannot be embedded due to licensing restrictions.。
simsun.ttc 不会抛出这个异常,不过参考「北京市高级人民法院(2010)高民终字第 772 号民事判决书」之类的材料:
在自行开发的软件中嵌入中易宋体需要额外授权,嵌入的定义包括:
- 在 Web 资源中引用本地托管的字体资源
- 在生成的文件中嵌入字体
如果你有版权方面的顾虑,笔者推荐使用 Google Noto CJK SC 字体。在页面上搜索并选择 Noto Sans Simplified Chinese(这是一种无衬线字体,中文字符应该是 Adobe 的思源黑体)和 Noto Serif Simplified Chinese(这是一种衬线字体,中文字符应该是 Adobe 的思源宋体),然后点击下载。*-Regular.ttf 足够应付大部分情况。
$ tree
.
├── Noto_Sans_SC
│ ├── NotoSansSC-VariableFont_wght.ttf
│ ├── OFL.txt
│ ├── README.txt
│ └── static
│ ├── NotoSansSC-Black.ttf
│ ├── NotoSansSC-Bold.ttf
│ ├── NotoSansSC-ExtraBold.ttf
│ ├── NotoSansSC-ExtraLight.ttf
│ ├── NotoSansSC-Light.ttf
│ ├── NotoSansSC-Medium.ttf
│ ├── NotoSansSC-Regular.ttf
│ ├── NotoSansSC-SemiBold.ttf
│ └── NotoSansSC-Thin.ttf
└── Noto_Serif_SC
├── NotoSerifSC-VariableFont_wght.ttf
├── OFL.txt
├── README.txt
└── static
├── NotoSerifSC-Black.ttf
├── NotoSerifSC-Bold.ttf
├── NotoSerifSC-ExtraBold.ttf
├── NotoSerifSC-ExtraLight.ttf
├── NotoSerifSC-Light.ttf
├── NotoSerifSC-Medium.ttf
├── NotoSerifSC-Regular.ttf
└── NotoSerifSC-SemiBold.ttf
至于楷体之类的字体,笔者在自己的项目中使用了来自 寒蝉字型项目 的字体;
在文档中嵌入外部资源
最简单的方法,不要在原始文档中链接外部资源。
HTML 文档可以使用内联样式,或在 <head> 标签中编写;SVG 本来就是 XML 元素,直接插入 DOM 树就行;大部分类型的图片如果是在线资源,可以直接使用 URL。
也可以转换成 Base64 字符串放在 src 属性中:
// avatar 对应了一个对象实例,其 handleAsImageSrcContent 方法返回图片 Base64 编码字符串
<img src="$avatar.handleAsImageSrcContent()"></img>
笔者为 cc.ddrpa.motto.html.embedded.EmbeddedImage 类创建了 toDataURL 方法,试图照着 velocity-engine-core/src/test/java/org/apache/velocity/test/util/introspection/ConversionHandlerTestCase.java 将其注册为 Apache Velocity 的 Type converter,不过没有成功,于是退而求其次重写了 toString 方法。
<img src="$avatar"></img>
那如果图片放在 resources 或者什么特定方式访问的地方呢?
Flying Saucer 使用 org.xhtmlrenderer.pdf.ITextUserAgent 处理输入文档中的嵌入资源。我们可以扩展 ITextUserAgent 实现自己的 UserAgent 来解析资源地址,通过不同的 protocol / schema / prefix 指定访问行为。
Logo 等静态资源,可以放在项目的 src/main/resources/ 目录中,在 HTML 文档中使用 <img src='resources://logo.jpeg' ... 引用。
src/ $ tree
.
├── main
│ ├── java
// ...
│ └── resources
│ └── logo.jpeg
// ...
在我们自己的 ResourcesUserAgent 中,匹配到具有 resources:// 前缀的资源路径后,可以通过 ClassLoader#getResourceAsStream 以流的形式获取到资源,之后照抄 ITextUserAgent#getImageResource 的实现就行:
@Override
public ImageResource getImageResource(String uriStr) {
if (!uriStr.startsWith(RESOURCES_PREFIX)) {
return super.getImageResource(uriStr);
}
String filePath = uriStr.substring(RESOURCES_PREFIX_LENGTH);
try (InputStream is = this.getClass().getClassLoader().getResourceAsStream(filePath);
ContentTypeDetectingInputStreamWrapper cis = new ContentTypeDetectingInputStreamWrapper(
is)) {
Image image = Image.getInstance(readBytes(cis));
scaleToOutputResolution(image);
return new ImageResource(uriStr, new ITextFSImage(image));
} catch (IOException e) {
XRLog.exception(
"Can't read image file; unexpected problem for URI '" + uriStr + "'", e);
return new ImageResource(uriStr, null);
}
}
动态获取的资源,如统计图表、用户上传内容等,可以预先保存到对象存储,然后使用 oss://$OBJECT_NAME 引用,方法也是一样的。
最后你需要在创建 ITextRenderer 时注册这个 UserAgent:
renderer = new ITextRenderer(ITextRenderer.DEFAULT_DOTS_PER_POINT,
ITextRenderer.DEFAULT_DOTS_PER_PIXEL, outputDevice,
new ResourcesUserAgent(outputDevice, ITextRenderer.DEFAULT_DOTS_PER_PIXEL),
fontResolver);
值得注意的是嵌入文档真就是字面上的「嵌入」,也就是说如果你的图片资源有 10 MB 之巨,那最终生成的文档也会大上 10 MB。motto-html 提供了一种压缩图片的方案,不过目前只能用于创建 EmbeddedImage 实例的场景,有需求的话可以实现一个能够压缩资源的 ResourcesUserAgent 并注册到 DocumentBuilder。
日志
Flying Saucer 附带了日志实现,不过默认是关闭的,你可以通过 xr.util-logging.loggingEnabled 属性开启。
static {
System.setProperty("xr.util-logging.loggingEnabled", "true");
}
在覆写 Flying Saucer 的行为时,推荐使用 org.xhtmlrenderer.util.XRLog 中的静态方法记录日志。
整点活
还记得 AcroForm 吗,这个标准的目的就是允许用户在 PDF 中填写表格然后保存(或者点击「提交」按钮将表单内容提交到服务器)。
User Guide 中的 Does Flying Saucer support PDF form components? 提到
… AcroForm support has been prototyped but not completed at this point.
那是因为文档有些滞后:
<input type="text" name="text-input" value="123" />
<input type="checkbox" name="checkbox-checked" checked="checked" />
<input type="checkbox" name="checkbox-unchecked" />
<input type="radio" name="radio-input" />
就能得到:

这些控件都是可以交互并保存填写值的。
不过笔者并没有测试在文件中嵌入 JavaScript 或是提交表单的功能。